Introduction
Unlambda is a venerable part of the esoteric programming languages canon. Billed as “Your Functional Programming Language Nightmares Come True”, Unlambda big distinction from most prior esolangs is that it is functional and based on a combinator calculus.
Much of the focus on the Unlambda page is on how to implement Unlambda, and it includes a question: “Can Unlambda be compiled?” Despite the Unlambda document suggesting “I don’t think it is possible to compile Unlambda”, this post answers the question in the affirmative by providing compilers for Unlambda into Standard ML, Lazy K (an excellent lazy functional esoteric programming language), and μUnlambda (a restriction of Unlambda that is obviously compilable and will be defined later in this post).
Code is available at https://github.com/msullivan/unlambda-compilers
During the seven-year gap between me starting writing this post and finishing it (near the very start of it), somebody wrote a bytecode compiler for Unlambda: https://terbium.io/2019/09/unlambda/ 1. Here I’ll make the answer a little more unambiguous by targeting several languages that have well-understood compilation strategies.
I only fully work through Unlambda 1.0, but I’ll discuss how to handle the input features.
AI Note
I didn’t use AI on this project or writing this post. Not using it for the code wasn’t really a thing of principle, but I started this project before AI and decided I should finish it without it. I think doing the core design here would not have been particularly have been fun using AI. (I wouldn’t be surprised if Sol and Fable could one shot this whole thing; I haven’t tried it. I also wouldn’t be that surprised if they said they solved it but produced something unsatisfying.) But I am also pretty sure that writing this blog post is going to be the last time in my life I write matplotlib graphing code by hand.
Unlambda to λ-Calculus
I’ll show how to compile Unlambda to the λ-calculus in 3 steps:
- Expand Unlambda to λ-Unlambda (the λ-calculus with all of unlambda’s built-ins added)
- Delay conversion, which compiles away the problematic delay (d) operator by adding a dummy argument to every function and forcing them at appropriate times. This is the main contribution of this post — this is the stage that was in question.
- CPS conversion, which compiles away the call/cc (c)
We take this approach for reasons of pedagogy and generality—another approach would be to explicitly give translated definitions for each combinator (and, in fact, the compilers to SML actually do work that way). By presenting it like this, we reduce the number of cases to consider, separate out the different jobs performed by each combinator, and are applicable to any language that might want a d operator.
That leaves us with a strictly evaluated λ-calculus with output functions.
Unlambda to λ-Unlambda
(Out of personal preference, and to more clearly distinguish them from variables, I am writing the unlambda combinators in uppercase instead of lower.)
This phase is straightforward — the S, K, I, and V combinators are all easily definable in the λ-calculus, and everything else is preserved.
I use a let expression for for clarity in V, but let x = m in n is equivalent to (λx.n)m
|I| = λx. x
|K| = λx. λy. x
|S| = λx. λy. λz. xz(yz)
|V| = let v = (λx. λy. xx) in vv
|e₁e₂| = |e₁| |e₂|
|C| = C
|D| = D
|.c| = .cDelay conversion
The key idea here is that each expression will be suspended by adding an extra dummy argument to it. This is sometimes known as “thunking”. Then, instead of evaluating the argument to a function when it is applied, the function being called will receive a suspended computation. The callee can then decide what to do with it: ordinary lambdas will force its evaluation immediately, while the d operator will delay evaluating it until the resulting function is evaluated.
All expressions in the untyped lambda-calculus can be seen as being of the recursive type F, where F = F → F. Delay conversion can be seen as rewriting that as F = unit → F → F.
The first two cases are simple. The variable case makes no changes. For application, we need to force the evaluation of the left hand side, pass in the right hand side, and force the evaluation of the result. Note that we don’t force evaluation of the right hand side!
|x| = x
|e₁e₂| = λ_. |e₁| () |e₂| ()(Here, () is written to indicate a contentless unit value. But since this really is an untyped lambda calculus, we don’t really have () — it could be any value. λx.x is the most obvious.)
The lambda case is the most interesting, because lambdas must evaluate their suspended argument. This must be done before evaluating the body of the lambda, because Unlambda is a call-by-value (eager) language.
After evaluating the suspended argument, we need to wrap it again, in a trivial function, to preserve the uniform representation of values.
|λx.e| = λ_. λy. let x = go y in |e| go e = let x = e () in λ_.xD, then, takes an argument and does not evaluate it until passed another argument:
|D| = λ_. λe. λ_. λx. let y in go x in e () y ()
(Fun fact: my initial implementation of this left off the go, meaning that the right hand side of the evaluation would be evaluated after the promise, not before.
|C| = λ_. λx. C (λk. x () (λ_. k))|.c| = λ_. λx. (.c) (go x)
CPS Conversion
There is nothing notable about CPS conversion here, but why not.
|x| = return x
|λx.e| = return λx.|e|
|e₁e₂| = λk. |e₁| (λx₁. |e₂| (λx₂. x₁ x₂ k))
|C| = return λf. λk. f (λy. λ_k. k y) k
|.c| = λy. λk. k (.c y)We define the return helper as
return e = λk. k e
And at the top-level, we run the program with:
|e| (λx.x)
This implementation of CPS conversion is totally unoptimized — it introduces a ton of new lambdas and then immediately applies them.
Delay conversion, version 2
The version of delay conversion presented above has the nice property of a fairly clean and uniform representation of values: everything is a function with an extra dummy argument.
There’s another approach that is in some ways easier to understand, though, which is to have values be tagged with whether they are a function or a delay. Then, application will case on that.
Here is that conversion:
|x| = x
|λx.e| = Inl (λx.|e|)
|e₁e₂| = let f₂ = λ_.|e₂| in
case |e1| of
Inl x => x (f₂ ())
Inr _ => λy. sap (f₂ ()) y
|D| = Inr ()
|C| = Inl (λx. C (λk. sap x (Inl k)))
sap v₁ v₂ = case v₁ of
Inl x => x v₂
Inr _ => v₂This requires a helper operation, sap, which does an application when the right-hand-side is already known to be a value, and so needn’t worry about delaying.
Here, Inl injects into the left branch of a sum, and Inr to the right. The left branch is used for functions, and the right for delay. The sums are encoded in the lambda calculus using the usual encoding:
Inl e = λl. λr. l e
Inr e = λl. λr. r e
case e of Inl l => e₁ | Inr r => e₂ = e (λl. e₁) (λr. e₂)λ-Calculus to μUnlambda
Having compiled away all of the built-in combinators except for the dot combinator, we could then compile back to a much-simplified version of Unlambda (that I will call μUnlambda) containing only s, k, i, and .x, by applying the “abstraction elimination” algorithm described in the Unlambda documentation.
We do not need to run through this entire compilation pipeline each time, though: with a bit of care to deal with application, we can build a direct character-for-character translation table from Unlambda to μUnlambda. Unfortunately doing this translation blows the program up quite a bit! (We could probably do a lot better by using a better CPS conversion algorithm.)
The size of each translated combinator:
` 279s 1971
k 623
i 289
d 647
c 357
v 1933
.! 300Supporting input for Unlambda 2.0
I don’t bother to show the details for how to support Unlambda 2.0 (which adds input features). Overall, there isn’t much difficult about it.
There’s an annoying snag when trying to do it for μUnlambda though, which is that we cannot directly use the definitions for input combinators from Unlambda 2.0.
Basically just to be difficult (since it is after all an esolang), Unlambda represents the booleans returned by the input functions as either i or v. It turns out, though, that these terms cannot be distinguished *except* by using call/cc (or some other form of side-effectful operation). Since we don’t want to support call/cc in μUnlambda, we need a different convention. This is easily resolved, though, by adjusting input functions for “μUnlambda 2.0” to use k and `ki as boolean values.
λ-Calculus to Lazy K
We can also compile into Lazy K, which is the lazy SKI combinator calculus in which the program is interpreted as a function from lists of church numeral inputs to lists of church numeral outputs. We simply modify the definition of the CPS conversion by having the dot function emit a cons cell containing the appropriate output numeral and the result of the continuation. We then apply abstraction elimination, as above.
|.c| = λy. λk. cons CH(c) (k y)
Compiling to Standard ML (SML)
Using the techniques above, I built three representations of Unlambda in Standard ML:
- Case-based, using call/cc
- Delay injection, using call/cc
- Delay injection, CPS converted
They can be used in two ways: either by building a program on the fly from an Unlambda AST and then running it, or by generating SML source code to be compiled separately.
They were all implemented manually, using the insights from the above techniques, not generated directly by them.
Is this better than an interpreter?
or
What, if anything, is a compiler?
Measurements
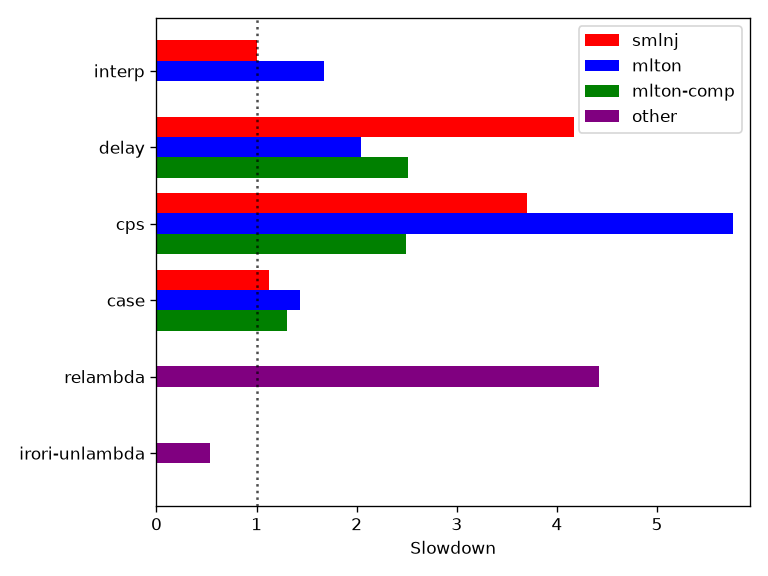
I did some half-assed benchmarking, running the prime_numbers.unl test from CUAN to generate 250 primes.
interp is a basic interpreter operating over AST-style data structures. delay, cps, and case are the versions discussed above. The smlnj and mlton versions of those compiled versions generate the “compiled” program at runtime and call it, while the mlton-comp version actually generates SML source code, compiles it, and runs it.
I also compare with relambda and with irori’s unlambda implementation. 2The c-refcnt implementation in the Unlambda distribution is about 25x slower and so was left out of the graph.
There’s not that much to compile!
In Unlambda, all we have is application of a small library of builtin functions. There are no user defined data structures, control flow, functions, etc.
The result of that is that there just isn’t much of a difference between what the compiled code is doing (especially in the fastest compiled version, the case based one) to apply a function and what the the interpreted one is doing: branching on the left hand side and then performing whatever the function’s action is. For a lot of cases, that just means constructing an object representing a partial application. There’s not that much difference between it being done via pattern matching and constructing explicit datatypes and it being done via directly calling functions.
In particular, in the particular case of implementing this in SML and compiling it with MLton, there is even less difference than you might think! MLton uses a technique called “defunctionalization” (wikipedia, paper on MLton’s implementation) to implement first-class functions, in which all of the possible functions being called at some call-site are bundled up into a datatype with their free variables. That datatype will look a lot like the datatype in the interpreter.
That said, the construction we presented was for “λ-Unlambda”, the lambda calculus extended with the Unlambda combinators, which actually is amenable to nontrivial compilation.
Vibes?
The first implementation of delay conversion–based on “thunking” all functions and having a uniform representation of values as thunked functions–feels more satisfying and more like a proper compilation stage to me than the second case-based version. I think this is because turning function application into a slightly more complicated function application feels to me more legitimate than turning a function application into a case.
This is despite it being worse! The case-based version runs faster and seems to be more amenable to optimizations.
I guess maybe I’m just stupid.
Compilation can be a spectrum
In 2009, I interned at Mozilla on the Javascript engine team 3. They had recently landed their first JIT, Tracemonkey, which worked really well for tight loops but compiled slowly and had some weird pathologies.
My task was to prototype a simpler JIT compiler that would compile code quickly and outperform the interpreter for code that wasn’t hot enough to be worth running the tracer on. The core of the technique they wanted me to implement was called “call threading”, which worked by essentially generating code that would make a series of calls to the interpreter’s implementations of each opcode. Implementations of branching opcodes would need to communicate whether to take the branch, but the interpreter opcode implementations handled basically all the work.
The goal here was to eliminate interpreter dispatch overhead and indirect branches. It succeeded at that, though on its own this was not enough to overcome all the new overhead added. Extending it to be able to directly generate inlined code for simple operations (interpreter stack manipulation, the integer case of arithmetic and comparisons, etc) managed to get some modest speedups—we called that version “inline threading”.
Were those compilers? Sure! Both of them generated machine code, but there’s some sense in which they feel a little unsatisfying. Both of them were totally driven by the interpreter’s object representations and data structures, and used the interpreter code for bread-and-butter operations like accessing a property on an object. And the “inline threading” version definitely compiled more than the “call threading” version.
Conclusion
- Unlambda can be compiled, to many different target languages that themselves have well known compilation strategies.
- Whatever that means.
- You could maybe argue that it doesn’t fully count as a compiler, since there is still a large case dispatch done on the
Functiondatatype (not just on theOpCodedatatype, which is the thing you’d imagine being compiled), but as I discuss in this post, it’s all a pretty fuzzy line in Unlambda-world. Matt’s general trick for implementing the delay operator seems to be pretty similar to the approaches I take. ↩︎ - irori has a bunch of very cool esolang projects, including high-performance interpreters for Unlambda and Lazy K, a port of Adventure to Unlambda, and a Haskell to Lazy K compiler.
↩︎ - Slides from my end-of-summer intern presentation. ↩︎